В 1958 году Даррел Хафф (Darrell Huff) написал бестселлер под названием «Как лгать при помощи статистики», поэтому для нашей эпохи «больших данных» подобные вещи необязательно являются чем-то новым. В настоящее время такой обман и искажения все еще практикуются, а в Сети можно найти уйму статей, посвященных некорректному использованию статистических данных.
Подтасовка данных может использоваться по самым разнообразным причинам. Вот некоторые из них:
- Источник является экспертом в предметной области, но не в сфере статистики.
- Источник является статистиком, но не экспертом в предметной области.
- Предмет изучения недостаточно хорошо определен.
- Низкое качество данных.
- Популярная пресса обладает ограниченным опытом и опирается на смешанные мотивы.
- «Политики используют статистику так же, как пьяница использует фонарные столбы — для поддержки, но не для освещения», — Эндрю Ленг (Andrew Lang).
Стоит также отметить, что в некоторых случаях люди слишком мотивированы, чтобы доказать свою точку зрения. Когда дело касается какой-либо дискуссии, данные могут послужить кому-то ценным аргументом, поэтому собеседники довольно часто искажают информацию. В интернет-маркетинге это приводит не только к неверной интерпретации результатов сплит-тестирования, но и к более серьезным проблемам.
Чтобы избежать предвзятого отношения к своим данным, вы должны следовать некоторым правилам. Ниже мы перечислили наиболее важные из них.
Всегда проверяйте выборку
При получении интересной статистики вам, прежде всего, нужно узнать, как были собраны эти данные. К примеру, для A/B-теста, поскольку вы не можете измерить истинный коэффициент конверсии, вам необходимо создать выборку, которая бы являлась статистической репрезентацией единого целого. Это касается всех методов сбора информации, включая опросы. Чаще всего выборка используется для получения ответов по всей аудитории.
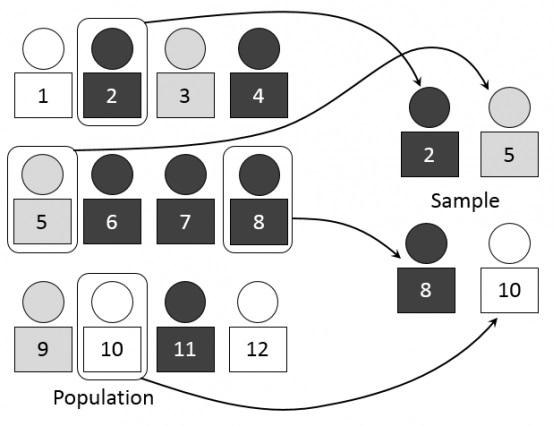
Чтобы объяснить эту концепцию, Мэтт Гершофф (Matt Gershoff) приводит пример с чашками кофе. Скажем, у вас есть 2 чашки кофе и мы хотим узнать, какая из них горячее и насколько. Вам нужно лишь измерить температуру обоих чашек и вычесть меньший показатель из большего, чтобы узнать разницу. Все очень просто.
Но если бы вы хотели выяснить, «где в вашем городе подается более горячий кофе, в McDonald's или Starbucks?», то столкнулись бы со статистической задачей. В таком случае вы должны были бы создать репрезентативную выборку, которая бы отражала результаты по всему населению. Чем больше чашек вы измеряете, тем больше вероятность того, что выборка показывает фактическую температуру.
В большинстве случаев проблема сводится к тому, что выборка оказывается недостаточно большой для получения достоверных результатов. Кроме того, маркетологи часто подбирают данные так, чтобы ответ соответствовал их изначальным ожиданиям.
Небольшие выборки
В ходе оптимизации конверсии небольшая выборка может запросто сбить вас с толку. Как гласит закон Тваймана, если данные кажутся вам слишком удивительными, скорее всего с ними что-то не так. Именно поэтому вы видите, как многие маркетологи дискредитируют тематические исследования компаний с абсурдными результатами (к примеру, увеличением конверсии на 400%).
Чтобы справиться с этой проблемой, всегда тщательно проверяйте собранную вами информацию и сохраняйте скептический настрой по отношению к чрезмерно завышенным цифрам.
Нерепрезентативные выборки
Обзорные опросы (Х процентов людей сказали Y) являются основной причиной использования нерепрезентативных выборок, и потому вы должны относиться к ним со всей осторожностью. Томи Местер (Tomi Mester), автор блога Data36, привел отличный пример с вымышленным персонажем Кларой, которой нужно провести исследование и выяснить, сколько времени студенты ее университета уделяют учебе, спорту и другим вещам. Она создала опрос и пытается собрать как можно больше ответов:
«Если она разошлет его своим друзьям и попросит их поделиться опросом с другими, он не будет охватывать аудиторию университета, только ее друзей и, возможно, друзей ее друзей. Это происходит потому, что добраться до людей из своего окружения она может с большей вероятностью, чем к кому-либо еще. Вы видите проблему?
Если Клара спортсменка, у нее могут быть друзья в баскетбольной команде (например), и в результате опрос покажет, что большинство студентов ее университета занимаются спортом. На самом же деле спортивный образ жизни ведут только ее друзья — что вовсе неудивительно, ведь спортсменкой в данном случае является именно она».
Подбор сегментов или искажение выборки
По сути, в попытках доказать определенную точку зрения вы можете искажать вашу выборку предвзятыми измерениями или подбирать конкретные факты в пользу своих предположений. Маркетологи могут подтасовывать данные с самого начала. Если вы создадите выборку, чтобы подкрепить свои предположения, то наверняка получите результаты, которые вас устроят.
- Опрашивая только ваших лучших клиентов, вы увидите, что большинству из них нравится ваше программное обеспечение.
- Анализируя только топовые когорты, вы легко докажете, что ваша кампания эффективна.
- Уделяя внимание только наиболее эффективным сегментам эксперимента, вы запросто назовете их победными.
Корреляция ≠ Причинно-следственная связь
Одной из самых распространенных ошибок при работе с данными является допущение о том, что корреляция подразумевает причинно-следственную связь. То, что две переменные имеют высокий коэффициент корреляции, не значит, что они связаны между собою каким-либо значимым образом. Для примера, взгляните на приведенный ниже график, который показывает, что фильмы Николаса Кейджа (Nicolas Cage) хорошо коррелируют с утоплениями в бассейне:
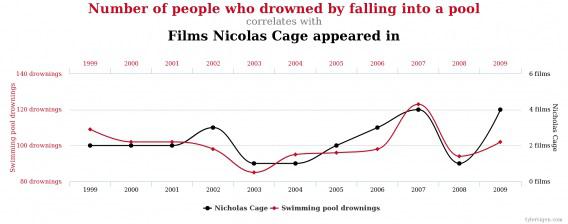
Корреляционные данные могут представлять огромную ценность, особенно в экспериментальном плане. Скажем, вы обнаружили, что люди, которые скачивают на вашем сайте некий PDF-файл, приносят вам больше денег в долгосрочной перспективе. Теперь вы могли бы провести простой эксперимент, чтобы побудить больше пользователей к загрузке этого документа, и посмотреть результаты.
Проблема здесь заключается в том, что зачастую такие корреляционные наблюдения берутся за основу. Ронни Кохави (Ronny Kohavi), заслуженный инженер компании Microsoft, привел следующий пример в недавней презентации:
«Чем больше ваша ладонь, тем меньше вы будете жить в среднем (с высокой статистической значимостью). Вы поверите, что в этом случае присутствует какая-либо причинно-следственная связь? Конечно же, нет. За основу здесь берется тот факт, что женщины с меньшими ладонями в среднем живут на 6 лет дольше. Но как насчет наблюдательных исследований о возможностях продукта, которые уменьшают отток?»
В своей книге «Как не ошибаться» (How Not to Be Wrong) Джордан Элленберг (Jordan Ellenberg) также предоставил отличный пример: предположим, у вас есть две бинарные переменные «курильщик ли вы?» и «женаты ли вы?».
После исследования (с правильной и репрезентативной выборкой) вы обнаруживаете, что в среднем курильщики с меньшей вероятностью заключают браки. Это сообщается в отчете, и именно здесь начинается путаница. Как говорит Элленберг, вы можете смело выразить это, сказав: «Если вы курильщик, у вас меньше шансов выйти замуж/пожениться».
Но всего лишь одно изменение в этом предложении могло бы существенно повлиять на его смысл: «Если бы вы были курильщиком, у вас было бы меньше шансов выйти замуж/пожениться».
Второе утверждение указывает на причинность, которая никак не подтверждалась в изначальном исследовании. Услышав его, многие пришли бы к следующему выводу: «Если вы курите, то скорее всего будете одиноки».
Post Hoc и другие методы сторителлинга
«После этого — значит по причине этого» (лат. post hoc ergo propter hoc) — апостериорная логическая ошибка, при которой корреляция принимается за причинную зависимость. Она возвращает вас во времени и говорит: «Это произошло раньше, поэтому оно послужило причиной тому, что последовало дальше».
По сути, это повествовательная ошибка, метод сторителлинга, с помощью которого вы можете объяснить прошлые события, хотя, вероятно, ваши пояснения и идут вразрез с реальным положением вещей. Вольтеровский «Кандидат» замечательно описывает post hoc заблуждение:
«Доказано, что все таково, каким должно быть; так как все создано сообразно цели, то все необходимо и создано для наилучшей цели. Вот, заметьте, носы созданы для очков, потому мы и носим очки».
В маркетинге можно легко сказать, что определенные действия привели к определенным результатам. К примеру, аналитические данные зачастую носят сезонный характер. Таким образом, если вы начинаете работать на спаде эффективности, скорее всего, вам будет казаться, что любое действие приводит к повышению ваших метрик:
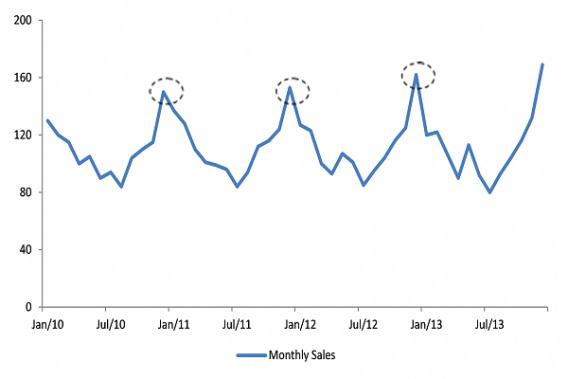
Во многом именно из-за этого маркетологи первым делом проводят сплит-тестирование. Если бы они могли просто изменить что-то на сайте и измерить влияние этих доработок без учета сезонности и внешних факторов, им было бы намного проще.
Помните, если вы меняете ваше главное изображение (без тестов), и ваша конверсия увеличивается, это необязательно значит, что причиной такого роста является новая картинка.
Средние значения могут вам лгать
Как гласит известная шутка: «Когда Билл Гейтс заходит в бар, каждый его посетитель становится миллионером...в среднем». Говоря в общем, среднее значение может характеризовать наиболее типичного представителя вашей аудитории. Но с математической точки зрения, средние показатели также делятся на 3 типа:
- Среднее арифметическое (mean average)
- Мода (mode average)
- Медиана (median average)
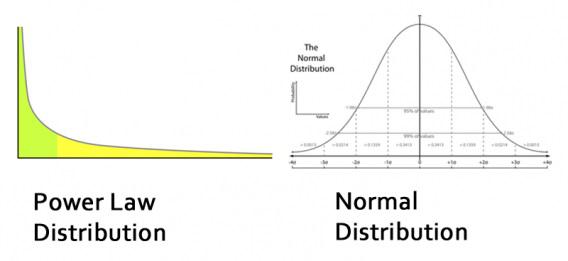
Если у вас есть набор чисел, скажем, 3, 3, 5, 4 и 7, среднее арифметическое будет равно 4,4 ((3+3+5+4+7)/5)), медиана — 4 (поскольку здесь есть 2 числа больше 4 и два числа меньше 4), а мода — 3 (так как эта цифра используется чаще всего). Чаще всего проблемы возникают тогда, когда вы выбираете показатель, который искажает среднее значение в наборе данных (как в примере с Биллом Гейтсом).
Наиболее распространенным примером является средняя заработная плата. В большинстве случаев зарплата представляет собой метрику, которая не поддается нормальному распределению — несколько человек зарабатывают больше денег, и это искажает среднее значение (mean).
Пиковые показатели могут влиять на результаты A/B-тестирования, особенно, когда вы занимаетесь оптимизацией таких метрик, как средний чек или доход на клиента.
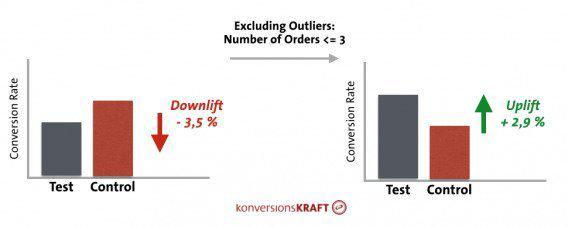
Кроме того, иногда за средними значениями CTR, показателя отказов или конверсии могут скрываться ценные инсайты — идеи, которые часто становятся первыми шагами на пути к созданию надежной программы персонализации.
Распространенные приемы визуализации данных, которых стоит остерегаться
Этому вопросу отводится целый раздел, потому что манипулировать данными, визуализируя их, очень просто. Визуализация данных — это один из способ сторителлинга, который можно использовать как в плохих, так и в хороших целях. Чаще всего этот метод реализуется весьма неумело, и вам приходится смотреть на кривые диаграммы, которые понятны разве что аналитикам:
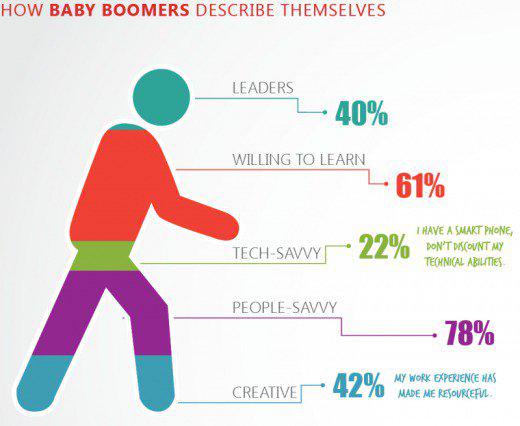
Как бэби-бумеры описывают сами себя: лидеры 40%, тяга к знаниям 61%, технически подкованы 22% (у меня есть смартфон!), разбираются в людях 78%, творческие 42% (мой опыт работы сделал меня находчивым)
Как ни странно, в большинстве случаев подобные диаграммы публикуются известными журналистами и СМИ. Возможно, они не понимают, в чем заключается их ошибка, а может быть, делают это намеренно, чтобы ввести аудиторию в заблуждение и получить больше кликов.
Круговые диаграммы
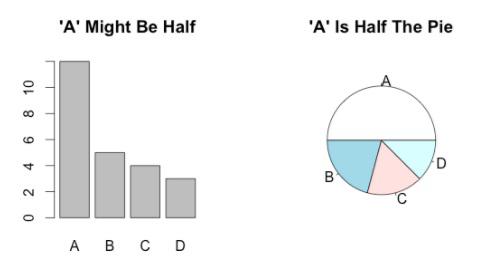
На самом деле вы должны всячески избегать использования круговых диаграмм. Почему? Потому что их трудно прочитать и они могут искажать пропорции. Взгляните на этот пример — сравниваемые круговые диаграммы здесь кажутся одинаковыми, тогда как столбчатые графики показывают совершенно другую историю:
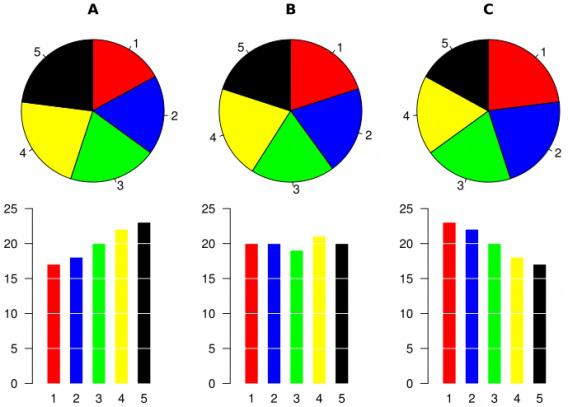
Еще хуже дела обстоят с трехмерными «пирогами». К примеру, в случае этой диаграммы вам может показаться, что голубой и красный сегменты одинаковы, хотя в количественном отношении они существенно отличаются:
Это не значит, что вы должны навсегда отказаться от такого метода визуализации данных. Он подходит для демонстрации простых пропорций:
Обрезанные оси
Если вы хотите, чтобы разница между двумя наборами данных казалась большей, чем она есть на самом деле, обрежьте диаграмму. Вот пример от Data36:
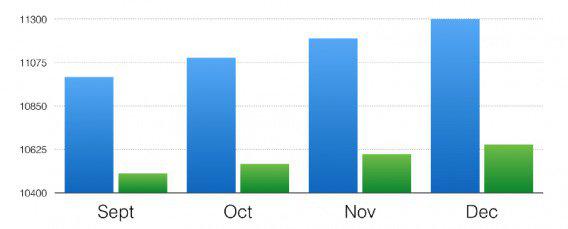
Большая разница, не так ли? Вот те же данные с осью Y, начинающейся с нуля:
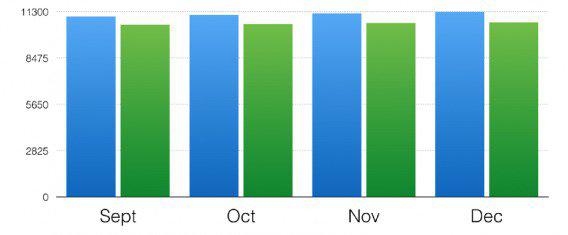
Имейте в виду, ваш способ визуализации данных может значительно повлиять на то, как потребители будут их интерпретировать.
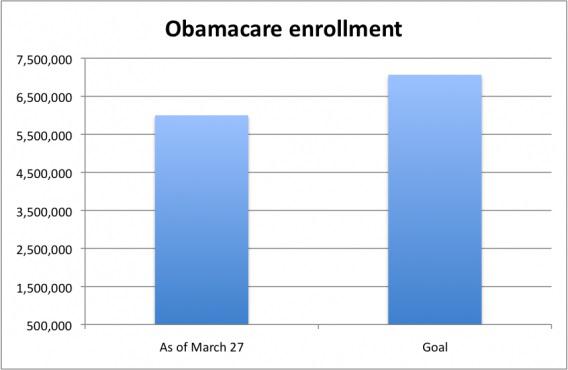
Вот график от Fox News:
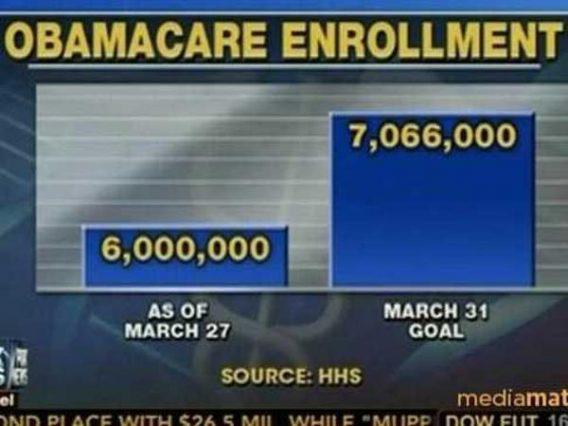
А вот как он выглядит на самом деле:
Делайте бизнес на основе данных!
По материалам: conversionxl.com.